Design a login feature using Twitter as an example
The following design assumes that you’re not able to leverage database, so basically, you need to design a database by your own to implement data storage and rollback etc features.
Scenario:
- Register/Update/Remove – All about user
- Login/Logout – All about session
- Balance/Membership – All about payment
Necessary – Register
Ask:
- Total users: 100,000,000
- Daily active users: 1,000,000
Predict:
- Daily active users in three months = 1,000,000 * 2 = 2,000,000
- Register rate = 1%
- Daily new register users = 2,000,000 * 1% = 20,000
Necessary – Login frequency
Predict:
- Login percentage = 15%
- Average login time = 1.2
- Daily login time = 2,000,000 * 15% * 1.2 = 360,000
- Average login frequency = 360,000 / 24hrs = 1,800,000/24/60/60 = 4.2/s
- Normal login frequency = 4.2 * 2 = 8.4/s
- Peak login frequency = 8.4 * 5 = 42/s
Application
Kilobit
Data – User V1:
class User {
int userId // Primary key
string name
string password // salted
}class UserTable {
vector<User> table
fun insert()
fun delete()
fun update()
fun select()
}Data – User V2:
Interviewer: how to support ban and delete?
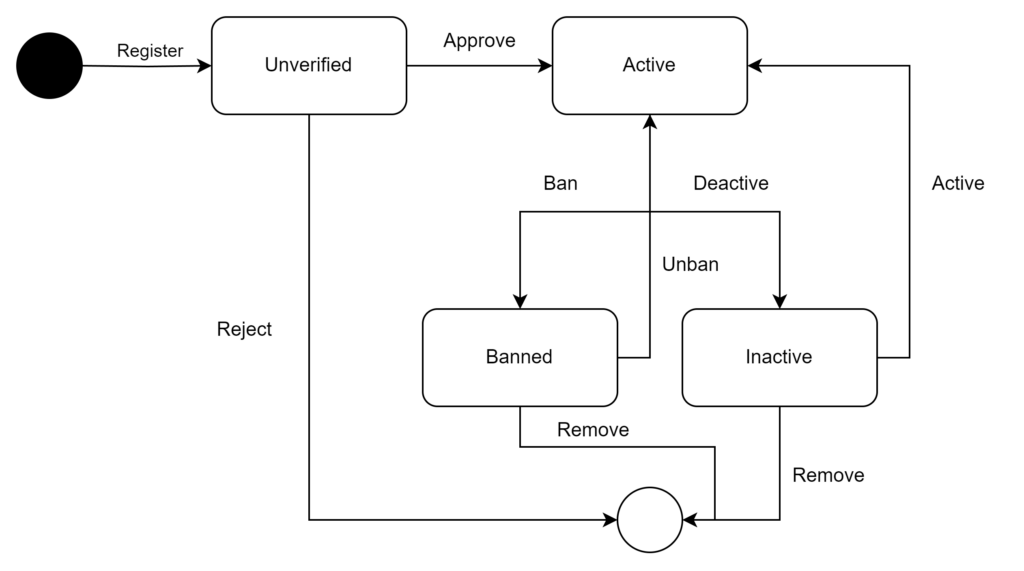
class User {
int userId // Primary key
char name[20]
char password[20] // salted
int status
}class UserTable {
vector<User> table
fun insert()
fun delete()
fun update()
fun select()
}Data – User V3:
Interviewer:
- A user will logout automatically after a period of time
- A user can login from multiple devices at the same time
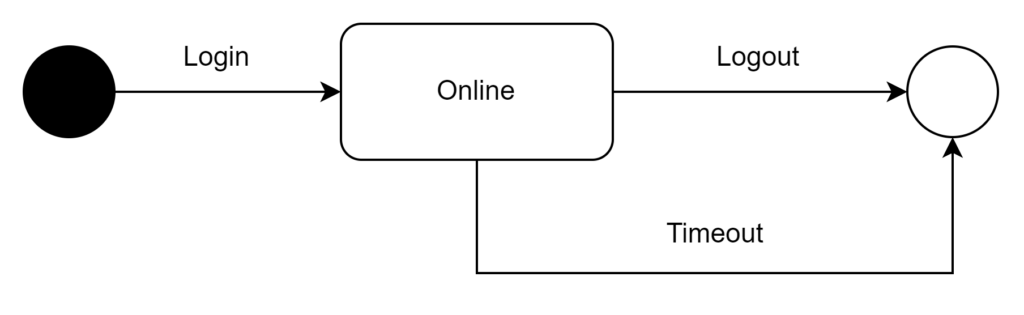
A session refers to a period of interaction between a user and a computer system or between two communicating computer systems.
A user can have multiple sessions when he/she logins from different devices at the same time.
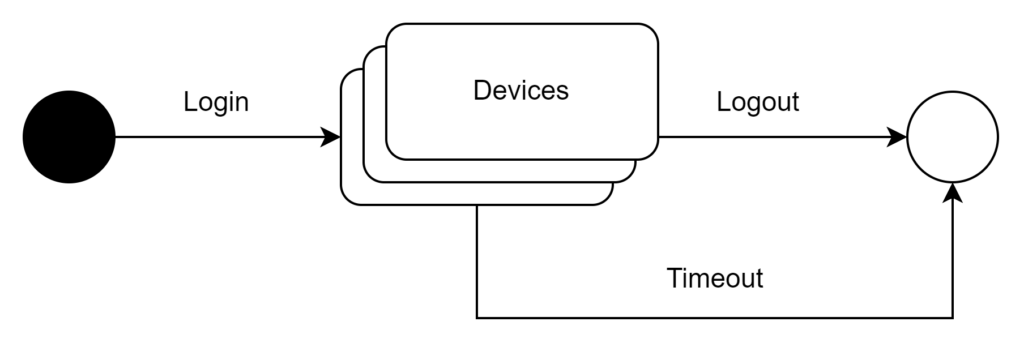
Session lifecycle graph V2
class User {
int userId // Primary key
char name[20]
char password[20] // salted
int status
vector<Session> sessionList
}class Session {
int sessionId
int userId
int deviceCode
time_t timeOut
}class UserTable {
vector<User> table
fun insert()
fun delete()
fun update()
fun select()
}The sessionList can be updated frequently; however, based on the current design, it may be time consuming to find a specific session.
Data – User V4:
To solve the concern from the previous version, we can create a new table for storing sessions.
class User {
int userId // Primary key
char name[20]
char password[20] // salted
int status
vector<Session> sessionList
}class Session {
int sessionId // Primary key
int userId
int deviceCode
time_t timeOut
}class UserTable {
vector<User> table
fun insert()
fun delete()
fun update()
fun select()
}class SessionTable {
vector<Session> table
fun insert()
fun delete()
fun update()
fun select()
}Data – User V5:
If we abstract the concept from previous version, then each row can be a record. By compositing rows, we can get UserTable and SessionTable
class Table {
vector<Row*> table
fun insert()
fun delete()
fun update()
fun select()
}class UserTable: Table {}
class SessionTable: Table {}class Row {
vector<Attribute*> row
}class User: Row {}
class Session: Row {}Interviewer:
- the name of the user whose userId = 21?
- the users whose userIds are within [4, 20]?
How to find the name of the user whose userId = 21?
Based on our current design, it need to loop through the records. Therefore, the time complexity is O(n)
How to speed up?
We can set index with hash. Hash the userId to build a hash table to look up. Via this approach the lookup time will be O(1).
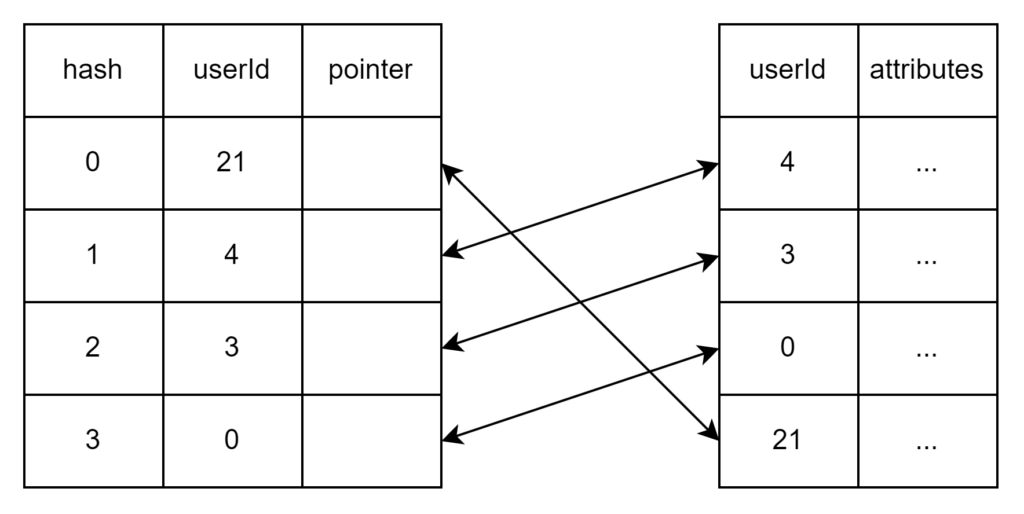
How to find the users whose userIds are within [4, 20]?
It’s a challenage to do range query via hash table that we demostrate in the previous question.
We can try to leverage other data structure such as Binary Search Tree.
Complexity:
- Space: O(n)
- Time of insert: O(log n)
- Time of delete: O(log n)
Disadvantages:
- Unbalanced data would lead Pathological tree
- Low fanout
In real world, B+Tree is a better solution. What’s B+Tree?
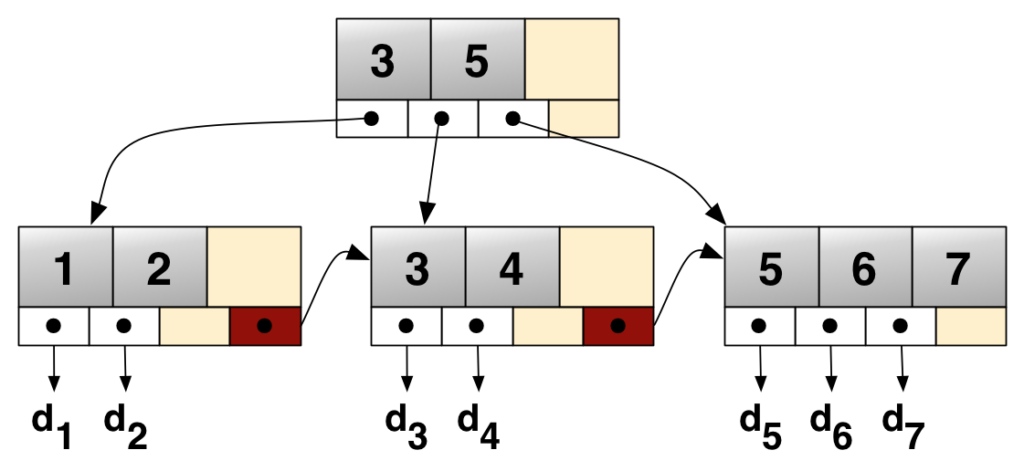
Characteristic:
- A self-balancing search tree data
- Internal nodes contain keys and pointers to child nodes
- Leaf nodes contain keys and data pointers. All leaf nodes are at the same level
- Keys in each node are stored in sorted order.
- Allow duplicate keys. Duplicate keys can be stored in the same node or in a linked list within a node.
- Due to the sorted order of keys in the leaf nodes, B+ trees support efficient range queries and sequential access.
- High fanout
Data – Membership
class Membership {
int userId
double money
time_t endTim e
fun addMoney()
fun buyMember()
}| UserId | money | endTime |
| 3 | 20 | 07/16/2016 |
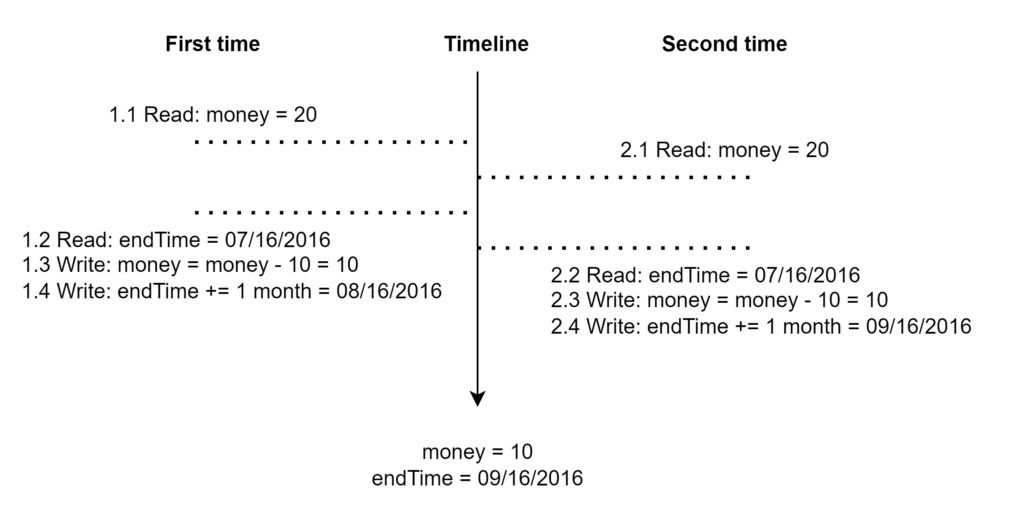
Happy path for buying membership:
- money = money – 10 = 10
- endTime += 1 month = 08/16/2016
- At the end:
- money = 10
- endTime = 08/16/2016
Exception:
- money = money – 10 = 10
- System goes down
- At the end:
- money = 10
- endTime = 07/16/2016
How to solve?
Ans: Add transaction with log
- Fixed exception:
- Write log
- Transaction_1123: BEGIN
- money = 20; endTime = 07/16/2016
- System goes down
- System goes up
- Read log
- Transaction_1123: BEGIN
- money = 20; endTime = 07/16/2016
- Recover
- money = 20
- endTime = 07/16/2016
- At the end
- money = 20
- endTime = 07/16/2016
- Read log
- Write log
- Happy path:
- Write log
- Transaction_1123: BEGIN
- moeny = 20; endTime = 07/16/2016
- money = money – 10 = 10
- endTime += 1 month = 08/16/2016
- Write log
- Transaction_1123: END
- money = 10; endTime = 08/16/2016
- At the end
- money = 10
- endTime = 08/16/2016
- Write log
Interviewer: What’s the problem in the following tables?
| userId | name | password | state |
| 4 | Sangpo | ***** | 1 |
| 3 | Steve | ***** | 2 |
| 0 | Jobs | ***** | 3 |
| userId | money | endTime |
| 3 | 20 | 07/16/2016 |
| 4 | 100 | 09/10/2016 |
| 4 | 40 | 08/15/2016 |
| 0 | 80 | 01/22/2016 |
| 6 | 0 | 03/25/2016 |
- userId 4 is duplicated in Membership table
- userId 6 is not existing in User table.
How to solve?
Ans: checker! It’s needed to pass all checkers before modification
class Checker {
vector<function*> checkList
fun register(fun* checkFunction) -> bool {}
}
Checker checker
checker.register(...checkUnknownUser(...) {...})
checker.register(...checkDuplicatedUser(...) {...})Interviewer: what if a user purchased membership twice in a short period of time?
| userId | money | endTime |
| 3 | 20 | 07/16/2016 |
How to solve?
Ans: Add lock

Til now, it’s time to talk about ACID and CAP
ACID
ACID is an acronym for a set of properties that guarantee the reliable processing of database transactions.
- Atomicity: All or nothing
- Consistency: Valid according to all defined rules
- Isolation: A kind of independency between transactions
Transactions are often executed concurrently (e.g., multiple transactions reading and writing to a table at the same time). Isolation ensures that concurrent execution of transactions leaves the database in the same state that would have been obtained if the transactions were executed sequentially. Isolation is the main goal of concurrency control; depending on the isolation level used, the effects of an incomplete transaction might not be visible to other transactions.[7]
https://en.wikipedia.org/wiki/ACID
- Durability: Stored permanently
CAP Theorem
The CAP theorem, also known as Brewer’s theorem, states that it’s impossible for a distributed system to simultaneously provide all three of the following guarantees: Consistency, Availability, Partition-Tolerance.
- Consistency: All nodes in the system see the same data at the same time.
- Availability: Every request for data receives a response, without guarantee that it contains the most recent version of the information.
- Partition Tolerance: The system continues to operate despite network partitions or communication failures between nodes.
There isn’t a system that can achieve all of three. Therefore, how to trade off is a key. In a distributed system, partition tolerance is a MUST. It means the system should continue to operate and make progress even if network partitions occur and lead some nodes can’t communicate with others.
Trade-off
- Consistency vs Availability
- Consistency Priority:
- Ensure all nodes in the system have the same view of the data at the same time, but might sacrifice availibilty in the event of network partitions or failures.
- Availability Priority:
- Ensure that every request for data receives a response, even if it may not reflect the most recent state of the data. Therefore, you might sacrifice consistency.
- Consistency Priority:
Interviewer: Design Paypal
For a payment system, there are key features:
- Send money
- Receive money
- Deposit money
- Withdraw money
Estimated QPS should be based on average daily active users.
For example:
Daily active user: 1,000,000
Deposit QPS = 1M (current daily active user) * 5 (potential future user increasement) * 1% (the percentage of active user that may operate deposit) * 1.1 (average times per user per day) / 86400 (second) = 1 QPS
There are many types of deposit such as deposit to your account, or others’ account etc.
Aim for depositing from my bank account to my Paypal account:
class User {
int userId // Primary key
...
// we should only focus on the feature that interviewer asked.
}class Order {
int orderId // Primary key
int bankId
int userId
double amount
int state
int operationType
time_t createdAt
time_t updatedAt
}class PaymentMethod {
int bankId // Primary key
string routingNumber
int userId
double limit
}Process:
- Log: ensure that we log every step, so we can track the dataflow
- Lock
- Load balance
- Update balance
- Unlock
- Submit
搶先發佈留言